Vertica Dimension Wars and Initial database tunning
Make Dimension table using the Dimension table design !!! I cannot stress enough about this. Dimension tables are typically small, ranging from a few to several thousand rows. Occasionally dimensions can grow fairly large, but this table are very skinny meaning this tables are not wide .
In Vertica we have UNSEGMENTED and SEGMENTED to ensure high availability and recovery
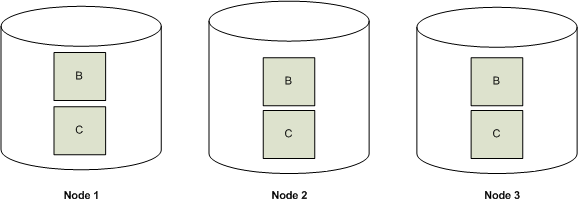
UNSEGMENTED projections:
- this type of projection design applies to small table like lookup tables or Dimension table, where the entire data set can be replicated across all nodes in the cluster.
- so in few words if you have a 3 node cluster with a k-safety of 1 you will have 3 copies of the table in each node.
SEGMENTED projections:
- this type of projection design applies to large table with many millions - billions - trill.... etc rows such as Fact Table.
What do you gain from doing this ?
- Ensures high availability and recovery through K-Safety.
- Spreads the query execution workload across multiple nodes.
- Allows each node to be optimized for different query workloads.
How can use properly segment our projections ?
In order to have a proper segmentation in place for a Fact table you need to provide even distribution of data across all nodes in the Cluster. Vertica provides you with the HASH function that provides even distribution of data across multiple nodes. The ideal candidate column for segmentation should be the primary key of your table or a combination of column that will be translated into a unique value after HASH has been applied to it. Note: - segmented projections that have low cardinallty columns in the segmentation clause suffer of Data Skew.What is Data Skew ?
Data skew is when your projection data is segmented in all nodes but the segments contain different amounts of data.- here is a graphical example of how a projection with bad segmentation looks like and we can see that data distribution is not even similar across nodes.
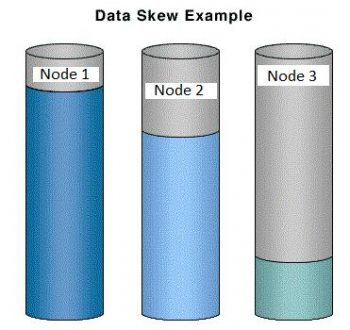
So how would data Skew affect my Vertica database ?
- well when issuing a query in Vertica the Initiator node will split the execution Workload across all nodes and some nodes might work more then other and bottom line is that your Vertica Cluster is as fast as your slowest node.
- where a single projection will have buddy projections spread across all nodes. If any one node will go down all data will be available since at least one buddy projection will be available.
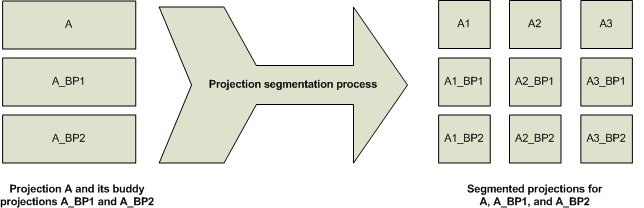
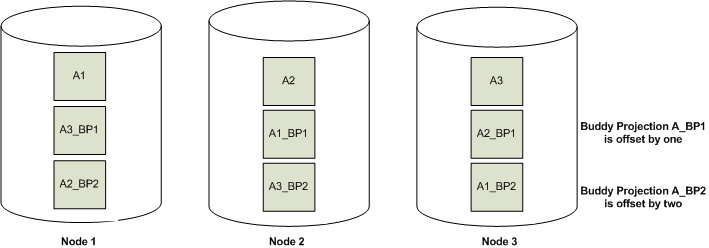 Disclaimer - the images used in this article belong to HP Vertica
After all the Projection bla bla bla .. "Hope this was helpful to some of you" we should get back to our bad Dimension design and see how we can find the bad Dimensions and how we can fix this.
Disclaimer - the images used in this article belong to HP Vertica
After all the Projection bla bla bla .. "Hope this was helpful to some of you" we should get back to our bad Dimension design and see how we can find the bad Dimensions and how we can fix this.
So lets get to work:
1 - Identify the Dimension tables with bad design If you are critical on table naming conventions : Use this Query to find Dimension tables that have segmented super projections.select
distinct projection_schema||'.'||anchor_table_name
from projections
where is_super_projection='true'
and is_segmented='true'
and anchor_table_name like 'Dim%'WITH
a AS
(
SELECT DISTINCT
projection_schema||'.'||anchor_table_name AS Tbl,
segment_expression
FROM
projections
WHERE
is_super_projection='true'
AND is_segmented='true'
)
,
b AS
(
SELECT
projection_schema||'.'||anchor_table_name AS Tbl,
SUM(row_count) AS rows
FROM
projection_storage
GROUP BY
projection_schema,
anchor_table_name
)
SELECT
b.Tbl,
b.rows,
a.segment_expression
FROM
a
JOIN
b
ON
a.Tbl=b.Tbl
WHERE
b.rows 0
AND b.rows < 1000000
ORDER BY
b.rows ASC2 - Identify the right order by keys (optimize query performance)
- best sort orders are determined by query WHERE clauses (or the so called predicates).- i am a firm believer that database performance is very dependent on your table design.
- this is query i have used for a couple of times:
SELECT DISTINCT
REPLACE(REPLACE(property_value,'(',''),')','')
FROM
dc_plan_step_properties
WHERE
property_name ='Filter'
AND property_value NOT ilike '%vs_%'
AND property_value NOT ilike '%dc_%'- this will output the columns used a filters in your queries.
3 - Prepare your new Projection Definition.
Before going ahead and change the table definition make sure you have picked-up the best encoding for the table. The best way to do this is by using DBD build-in function called DESIGNER_DESIGN_PROJECTION_ENCODINGS.- this function will analyze your table and data and will come up with the best encoding fit.
select DESIGNER_DESIGN_PROJECTION_ENCODINGS ('schema.table','/tmp/schema.table.sql','true');