What are the Data compression and encoding types in Vertica
In this tutorial we will cover the encoding and compression in Vertica. We will explain what they are and how they work in Vertica's arch.
Encoding
Is the process of converting data into a standard format. Vertica uses a number of different encoding strategies, depending on column data type, table cardinality, and sort order.
Encoded data can be processed directly by Vertica.
Compression
Is process of transforming data into a compact format.
Compressed data cannot be directly processed by Vertica. Data must first be decompressed.
Encoding-type
It serves as the default if no encoding/compression is specified. Lempel-Ziv-Oberhumer-based (LZO) compression is used
for CHAR/VARCHAR, BOOLEAN, BINARY/VARBINARY, and FLOAT columns.
Encoding Auto is ideal for sorted, many-valued columns such as primary keys.
Stores only the differences between sequential data values instead of the values themselves. This encoding type is
best used for integer-based columns, but also applies to DATE/TIME/TIMESTAMP/INTERVAL columns. It has no effect on other data types.
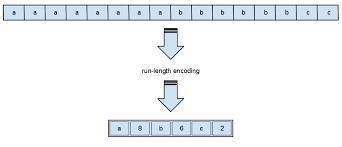
Run length encoding stands out from other methods of compression.It replaces identical values(runs) with a single pair that contains the value and number of occurrences
Is best used for low cardinality columns that are present in the ORDER BY clause of a projection.
For each block of storage, Vertica compiles distinct column values into a dictionary and then stores the dictionary and a list of indexes to represent the data block.
Is ideal for few-valued, unsorted columns in which saving space is more important than encoding speed. BINARY/VARBINARY columns do not support BLOCK_DICT encoding.
This encoding type is similar to BLOCK_DICT except that dictionary indexes are entropy coded. This encoding type requires significantly more CPU time to encode and decode and has a poorer worst-case performance. However, use of this type can lead to space savings if the distribution of values is extremely skewed.
Is ideal for many-valued FLOAT columns that are either sorted or confined to a range. Do not use it with unsorted columns that contain NULL values, as the storage cost for representing a NULL value is high.
It has a high cost for both compression and decompression.
- ENCODING COMMONDELTA_COMP
Is ideal for sorted FLOAT and INTEGER-based (DATE/TIME/TIMESTAMP/INTERVAL) data columns with predictable sequences and only the occasional sequence breaks, such as timestamps recorded at periodic intervals or primary keys.
Is very CPU intensive
Do not specify this value. Increases space usage, increases processing time, and leads to problems
