How to Install Apache Hadoop on Linux Centos 6 Single Node
HDFS or "Hadoop Distributed File System" is a distributed file-system that stores data on commodity machines, providing very high aggregate bandwidth across the cluster. HDFS was inspired in the Google File System, HDFS stores large files (typically in the range of gigabytes to terabytes) across multiple machines. It achieves reliability by replicating the data across multiple hosts, and hence theoretically does not require RAID storage on hosts (but to increase I/O performance some RAID configurations are still useful). With the default replication value, 3, data is stored on three nodes: two on the same rack, and one on a different rack. Data nodes can talk to each other to re-balance data, to move copies around, and to keep the replication of data high. We going to see in this tutorial how we can install HDFS in a single node cluster and we will see the overall configuration of HDFS only required to start working with HDFS.
These are the steps you need to take to install and configure HDFS on a Linux Centos Box.
1 - Install Java
Java is a requirement for running Hadoop on any system, So make sure you have Java installed on your system using following command.yum install java-1.8.0-openjdk.x86_64 -y2- Create a user called hadoop
We will create the user hadoop and a group hadoopgrp, next will add the hadoop user to the hadoopgrp group.[root@localhost ~]# useradd hadoop
[root@localhost ~]# groupadd hadoopgrp
[root@localhost ~]# gpasswd -a hadoop hadoopgrp3 - Enable ssh-password-less to the host to user hadoop
You will require this access for the hadoop instalation, simply follow the step bellowsu - hadoop
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keysValidate ssh access;
Accept and continue.[hadoop@localhost ~]$ ssh 192.168.15.167
The authenticity of host '192.168.15.167 (192.168.15.167)' can't be established.
RSA key fingerprint is 10:e4:4e:f7:3b:ab:ad:2c:d1:2d:8a:cb:22:61:82:ce.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '192.168.15.167' (RSA) to the list of known hosts.
[hadoop@localhost ~]$4 - Download the lasted stable version of Hadoop
Download , untar and move the hadoop distribution.wget http://apache.claz.org/hadoop/common/hadoop-2.7.3/hadoop-2.7.3-src.tar.gz
tar xzf hadoop-2.7.3-src.tar.gz
mv hadoop-2.7.3/ /home/hadoop/hadoop5 - Setup the Hadoop environment variables
Append the following to the /home/hadoop/.bashrc file. Make sure you have your path to the hadoop home as bellow otherwise you need to change it to apply to your hadoop home path.export HADOOP_HOME=/usr/local/lib/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/binsource .bashrc6 - Set the Java home to the Hadoop eenvironment
You need to look for the hadoop-env.sh file and edit the JAVA_HOME parameter value.find /usr/local/ -name hadoop-env.sh
--output
/usr/local/lib/hadoop/etc/hadoop/hadoop-env.shjava -showversion -verbose 2&1 | head -1
--output
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.101-3.b13.el6_8.x86_64# The only required environment variable is JAVA_HOME. All others are
# optional. When running a distributed configuration it is best to
# set JAVA_HOME in this file, so that it is correctly defined on
# remote nodes.
# The java implementation to use.
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.101-3.b13.el6_8.x86_64
# The jsvc implementation to use. Jsvc is required to run secure datanodes
# that bind to privileged ports to provide authentication of data transfer
# protocol. Jsvc is not required if SASL is configured for authentication of7 - Edit the core-site.xml file located in the same path as the hadoop-env.sh
Core-site.xml is the configuration file where you keep all your HDFS related configurations. Example: Namenode host and port, the local directory where NameNode related stuff can be saved etc.<?xml version="1.0" encoding="UTF-8"?
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
--
<!-- Put site-specific property overrides in this file. --
<configuration
<property
<namefs.default.name</name
<valuehdfs://localhost:9000</value
</property
</configuration8 - Edit the hdfs-site.xml file.
Before we go ahead and edit this file we need to create the location that will contain the namenode and the datanode for this Hadoop installation.sudo mkdir -p /hdoop_store/hdfs/namenode
sudo mkdir -p /hadoop_store/hdfs/datanode
sudo chown -R hadoop:hadoopgrp /hadoop_store<!-- Put site-specific property overrides in this file. --
<configuration
<property
<namedfs.replication</name
<value1</value
</property
<property
<namedfs.name.dir</name
<valuefile:/hdoop_store/hdfs/namenode</value
</property
<property
<namedfs.data.dir</name
<valuefile:/hdoop_store/hdfs/datanode</value
</property
</configuration
~9 - Edit the mapred-site.xml file.
The mapred-site.xml file is used to specify which framework is being used for MapReduce. First find the mapred-site.xml.template and create the file mapred-site.xml out of it.cp mapred-site.xml.template mapred-site.xml<!-- Put site-specific property overrides in this file. --
<configuration
<property
<namemapred.job.tracker</name
<valuelocalhost:54311</value
</property
</configuration10 - Format the file system that we allocated to hdfs
This set of commands should be executed once before we start using Hadoop. If this command is executed again after Hadoop has been used, it'll destroy all the data on the Hadoop file system.[hadoop@dhcppc4 hadoop]$ hadoop namenode -format
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
16/09/14 18:12:26 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = hdp.domain.com/127.0.0.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.7.0
.........................
.........................
16/09/14 18:12:27 INFO util.GSet: 0.029999999329447746% max memory 889 MB = 273.1 KB
16/09/14 18:12:27 INFO util.GSet: capacity = 2^15 = 32768 entries
16/09/14 18:12:27 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1656316296-127.0.0.1-1473840747357
16/09/14 18:12:27 INFO common.Storage: Storage directory /hadoop_store/hdfs/namenode has been successfully formatted.
16/09/14 18:12:27 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid = 0
16/09/14 18:12:27 INFO util.ExitUtil: Exiting with status 0
16/09/14 18:12:27 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hdp.domain.com/127.0.0.1
************************************************************/11- Start Hadoop
To start Hadoop you need to use the start-all.sh script, this script is located in the sbin directory of your hadoop installation[hadoop@dhcppc4 sbin]$ ./start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
16/09/14 18:17:06 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [localhost]
localhost: starting namenode, logging to /usr/local/lib/hadoop/logs/hadoop-hadoop-namenode-hdp.domain.com.out
localhost: starting datanode, logging to /usr/local/lib/hadoop/logs/hadoop-hadoop-datanode-hdp.domain.com.out
Starting secondary namenodes [0.0.0.0]
The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established.
RSA key fingerprint is 10:e4:4e:f7:3b:ab:ad:2c:d1:2d:8a:cb:22:61:82:ce.
Are you sure you want to continue connecting (yes/no)? yes
0.0.0.0: Warning: Permanently added '0.0.0.0' (RSA) to the list of known hosts.
0.0.0.0: starting secondarynamenode, logging to /usr/local/lib/hadoop/logs/hadoop-hadoop-secondarynamenode-hdp.domain.com.out
16/09/14 18:17:26 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
starting yarn daemons
starting resourcemanager, logging to /usr/local/lib/hadoop/logs/yarn-hadoop-resourcemanager-dhcppc4.out
localhost: starting nodemanager, logging to /usr/local/lib/hadoop/logs/yarn-hadoop-nodemanager-hdp.domain.com.out[hadoop@dhcppc4 bin]$ netstat -plten | grep java
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 0 0 127.0.0.1:60818 0.0.0.0:* LISTEN 500 210996 19520/java
tcp 0 0 0.0.0.0:50070 0.0.0.0:* LISTEN 500 209866 19395/java
tcp 0 0 0.0.0.0:50010 0.0.0.0:* LISTEN 500 210990 19520/java
tcp 0 0 0.0.0.0:50075 0.0.0.0:* LISTEN 500 211211 19520/java
tcp 0 0 0.0.0.0:50020 0.0.0.0:* LISTEN 500 211214 19520/java
tcp 0 0 127.0.0.1:9000 0.0.0.0:* LISTEN 500 209881 19395/java
tcp 0 0 0.0.0.0:50090 0.0.0.0:* LISTEN 500 212636 19689/java12 - Stop the Hadoop services
[hadoop@dhcppc4 sbin]$ ./stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
16/09/14 18:24:14 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Stopping namenodes on [localhost]
localhost: stopping namenode
localhost: stopping datanode
Stopping secondary namenodes [0.0.0.0]
0.0.0.0: stopping secondarynamenode
16/09/14 18:24:34 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
stopping yarn daemons
stopping resourcemanager
localhost: stopping nodemanager
no proxyserver to stop
[hadoop@dhcppc4 sbin]$ netstat -plten | grep java
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)13 - Using the Hadoop Web interface.
For this we need to start the hadoop services and access the 50070 port.[hadoop@dhcppc4 sbin]$ ./start-dfs.sh
16/09/14 18:26:31 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [localhost]
localhost: starting namenode, logging to /usr/local/lib/hadoop/logs/hadoop-hadoop-namenode-hdp.domain.com.out
localhost: starting datanode, logging to /usr/local/lib/hadoop/logs/hadoop-hadoop-datanode-hdp.domain.com.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/lib/hadoop/logs/hadoop-hadoop-secondarynamenode-hdp.domain.com.out
16/09/14 18:26:48 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[hadoop@dhcppc4 sbin]$ netstat -plten | grep java
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 0 0 0.0.0.0:50070 0.0.0.0:* LISTEN 500 428438 20914/java
tcp 0 0 0.0.0.0:50010 0.0.0.0:* LISTEN 500 429667 21044/java
tcp 0 0 0.0.0.0:50075 0.0.0.0:* LISTEN 500 429889 21044/java
tcp 0 0 127.0.0.1:56285 0.0.0.0:* LISTEN 500 429673 21044/java
tcp 0 0 0.0.0.0:50020 0.0.0.0:* LISTEN 500 429895 21044/java
tcp 0 0 127.0.0.1:9000 0.0.0.0:* LISTEN 500 428453 20914/java
tcp 0 0 0.0.0.0:50090 0.0.0.0:* LISTEN 500 431025 21213/java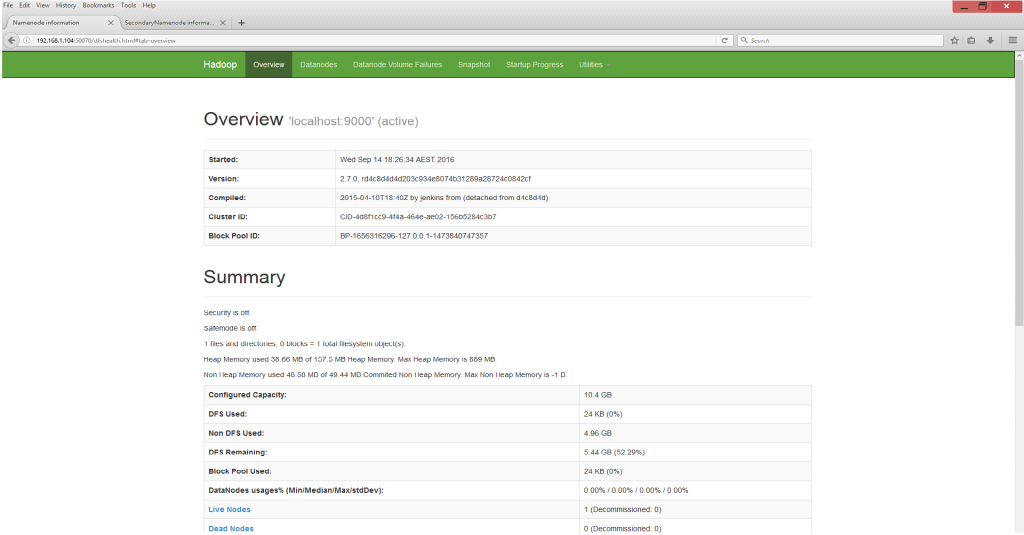 So we have installed our Hadoop instance and we have it up and running.
Now days we have Hortonworks, CLaudera,MapR that have nice GUI tools to help us with the Hadop eco-system installations but i belive that every Hadoop Admin or wnabe Hadoop admin should know how do all this tasks and understand each component involved in this task.
In next tutorials we will see how to run a MapReduce job in Hadoop.
So we have installed our Hadoop instance and we have it up and running.
Now days we have Hortonworks, CLaudera,MapR that have nice GUI tools to help us with the Hadop eco-system installations but i belive that every Hadoop Admin or wnabe Hadoop admin should know how do all this tasks and understand each component involved in this task.
In next tutorials we will see how to run a MapReduce job in Hadoop.
