Fix for AWS EC2 instance stuck in Initializing state
In this article we will see how we can start an AWS EC2 instance for a non-stop state of Initializing. Causes for this type of EC2 instance behavior are listed at this link EC2 tourbleshooting and came well detailed by AWS documentation. But in some cases like mine there is no official troubleshoot done. So here is what i got in my System Log.
- to get your EC2 system log you select it from the EC2 instance option list.
 And here is the content of the log, just the part we are interested in:
And here is the content of the log, just the part we are interested in:
[ 4.352948] cirrus 0000:00:02.0: registered panic notifier
[ 4.352952] [drm] Initialized cirrus 1.0.0 20110418 for 0000:00:02.0 on minor 0
[ 4.409799] xvde: unknown partition table
[ 93.960199] type=1305 audit(1453357323.599:3): audit_pid=538 old=0 auid=4294967295 ses=4294967295 res=1
Give root password for maintenance
(or type Control-D to continue):- it looks like the volume xvde has some problems. And this affects the entire host.
- the host is not reachable !
- i cannot edit the /etc/fstab file and remove the xvde entry !
- the root volume holds the /etc/fstab file.
 3 - Attach the detached volume to the instance we started at step 1.
3 - Attach the detached volume to the instance we started at step 1.
- choose instance form drop down list.
- choose the volume name as /dev/sdx (easy to spot)
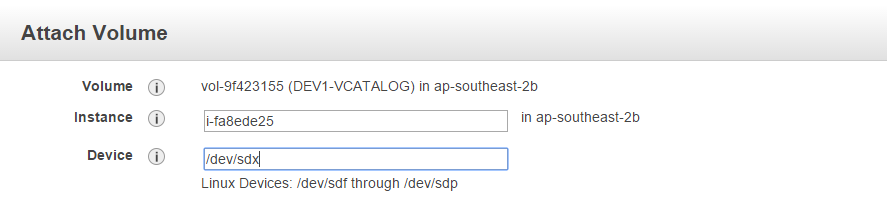 4 - Login to your new instance and list the volumes attached to the instance using the lsblk command.
4 - Login to your new instance and list the volumes attached to the instance using the lsblk command.
[root@aodba]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
xvda 202:0 0 8G 0 disk
└─xvda1 202:1 0 8G 0 part /
xvdx 202:80 0 15G 0 disk
├─xvdx1 202:81 0 1M 0 part
└─xvdx2 202:82 0 6G 0 part - you dont need to format the disk, this will erase the data.
- the /dev/xvdx2 volume content are reachable to you now to edit.
- edit the /etc/fstab file and remove the entry with the failed disk.
[root@aodba]# mkdir /rest
[root@aodba]# mount /dev/xvdx2 /rest/
--edit fstab file
[root@aodba]# vim /rest/etc/fstab6 - Un-mount the /dev/xvdx2 volume and detach it from the new instance.
7 - Reattach the volume back to your failing instance.
Note:
- you have to attach the volume as /dev/xvda.
- your host should up and running.
