HP Vertica Database Key Components
Key components in HP Vertica
Compression Encryption is the process of converting data to a standard format. In Vertica the encoded data can be directly processed as the compressed data can not. HP Vertica uses a number of different encoding strategies, depending on the type of data column, the cardinality of the table, and sort order. Encoding is one way to make a more compact column. The coding is the same as the compression. Vertica uses encrypted data saving memory and bandwidth. In contrast, traditional databases need to decrypt the data before performing any operation. Compression Compression is the data transformation process in a compact format. The compressed data can not be directly processed; it must first be decompressed. Although compression is generally considered to be a form of encoding, the terms have different meanings in Vertica. Efficient storage that Vertica adopts allows the database administrator to keep the data stored for much more time. K-SAFETY K-SAFETY is a fault tolerance measure in the database cluster. The value of K represents the number of replicas of the data in the database that are in the cluster. These replicas allow other nodes take over the nodes that failed, allowing the database to continue working and still ensure data integrity. If more than K cluster in will fail, some data may become unavailable. In this case, the database is considered unsafe and off automatically. Let's go into more detail about the concept and K-SAFETY in future articles. Projections A projection may be associated with a materialized view that provides physical storage of data. The projection may contain some or all of the columns of one or more tables. The projection that contains all the columns of a table is called super-protection. A projection that joins one or more tables is called pre-join projection. The projections are a very important part in the HP Vertica architecture, we will talk more about projections in future articles. Hybrid Storage Model To support data manipulation operations (DML) type (INSERT, UPDATE, and DELETE) and cargo operations of large volumes, with running queries without loading windows that are common in a data warehouse environment, Vertica implements the storage model shown in the illustration below. This model is the same on every HP Vertica node.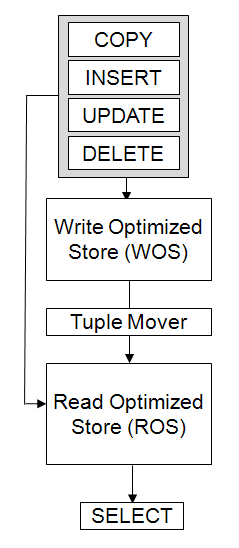 Write Optimized Store
Write Optimized Store (WOS) is a data structure that resides in memory to store data through commands such as INSERT, UPDATE, DELETE, and COPY (without using the hint "DIRECT").
To support large data load speeds, the WOS storage type records data without compression or indexing. The projection in the WOS will be ordered only when it will be used for queries.
The data stored in WOS remain ordained in projection, since no further data is entered. The WOS organizes data by EPOCH and keep both transaction data consolidated and unconsolidated data.
Read Optimized Store
Storage Read Optimized Store (ROS) is highly optimized, specifically oriented for reading, the disk storage structure, organized by the projection.
The ROS makes heavy use of compression and indexing. In order to load the right data storage ROS you can use the hint (/ * + * direct /) with the load commands and insert commands.
Tuple Mover
The Tuple Mover (TM) is the component with the optimization of the data stored by the HP Vertica. The work of the Tuple Mover (TM) and move the data from memory (WOS) to disk (ROS).
TM also combines small containers (containers) ROS in greater; and also he and responsible with the purge of deleted data.
The process Tuple Move (TM) consists of two operations:
Write Optimized Store
Write Optimized Store (WOS) is a data structure that resides in memory to store data through commands such as INSERT, UPDATE, DELETE, and COPY (without using the hint "DIRECT").
To support large data load speeds, the WOS storage type records data without compression or indexing. The projection in the WOS will be ordered only when it will be used for queries.
The data stored in WOS remain ordained in projection, since no further data is entered. The WOS organizes data by EPOCH and keep both transaction data consolidated and unconsolidated data.
Read Optimized Store
Storage Read Optimized Store (ROS) is highly optimized, specifically oriented for reading, the disk storage structure, organized by the projection.
The ROS makes heavy use of compression and indexing. In order to load the right data storage ROS you can use the hint (/ * + * direct /) with the load commands and insert commands.
Tuple Mover
The Tuple Mover (TM) is the component with the optimization of the data stored by the HP Vertica. The work of the Tuple Mover (TM) and move the data from memory (WOS) to disk (ROS).
TM also combines small containers (containers) ROS in greater; and also he and responsible with the purge of deleted data.
The process Tuple Move (TM) consists of two operations:
- -Moveout
- -Mergeout
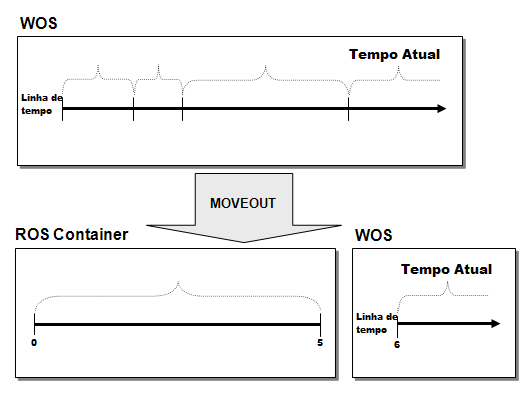 The moveout operation will carry all the WOS storage for the historical data store ROS.
ROS Container
A Container ROS (Read Optimized Store) is a set of rows stored in a specific group of files. Containers ROS are created by transactions such as moveout or direct copy for ROS (using i hint DIRECT)
The organization of ROS Containers may be different in other nodes due to the variation of the data. Segmentation can offer more lines to the other node. Two loads could fit in WOS on a node and can leak or create a data spill in the other.
Mergeout
The moveout operation will carry all the WOS storage for the historical data store ROS.
ROS Container
A Container ROS (Read Optimized Store) is a set of rows stored in a specific group of files. Containers ROS are created by transactions such as moveout or direct copy for ROS (using i hint DIRECT)
The organization of ROS Containers may be different in other nodes due to the variation of the data. Segmentation can offer more lines to the other node. Two loads could fit in WOS on a node and can leak or create a data spill in the other.
Mergeout
The mergeout is the ROS containers consolidation process and the process of purging the deleted records. Over time, the number of containers increases ROS to a degree that it becomes necessary to create a melting some of the ground and avoid performance degradation. At this point, the process performs an automatic Tuple Move mergeout that combines two or more ROS containers in a single container. This process can be considered as "defragmenting" ROS storage. Vertica keeps data separated in different partitions on the disk. When the process of Tuple Move consolidates ROS containers, he adhered to this Statement does not found ROS containers of different partitions. When a partition is created the first time, is usually subject to frequent data loads and requires regular attention from the Tuple Mover process. As with the old partition, there is a work load change reading the further specifies that requires less attention from the tuple Move process. The process of Tuple Move has two different policies to manage workloads in different partitions:
- In active partitions that are uploaded or modified frequently. The process uses a Tuple Move STRATA mergeout policy that maintains a collection of ROS sizes of containers to minimize the number of times any mergeout tuple is subjected to the process.
- In inactive partitions that are rarely loaded or modified. The process of Tuple Move consolidates ROS containers to a minimum set, preventing the merger containers with size that exceeds a specified value by the value of the parameter MaxMrgOutROSSizeMB.
- If a partition was created before the other partition, he is older.
- If two partitions are created at the same time, but a partition was updated earlier than the other partition, he is older.
- If two partitions are created and updated while the partition with the smallest key is considered big.
- If you run a manual mergeout using DO_TM_TASK function, all partitions are consolidated in the smallest possible number of containers, regardless of the value of the parameter ActivePartitionCount.
